
A Memory-Aware Runtime for Running Large Language Models Locally
A Memory-Aware Runtime for Running Large Language Models Locally

Large Language Models are powerful, but they are difficult to run.
Many open-source models are available today, but running them is still a problem for many developers. Large models need a lot of memory. They need GPU memory, system RAM, or both. A good GPU is expensive. Cloud GPUs are also expensive.
Because of this, many developers face the same problem:
The model is available, but my machine cannot run it properly.
LayerRun is built to solve this problem.
LayerRun is a local LLM runtime designed to make large model execution more flexible, more transparent, and more memory-aware. Its goal is to help developers run and serve language models without always needing to load the full model into memory at once.
LayerRun is not only a low-level experiment. It is becoming a product for local AI execution.
The main idea is simple:
Run models in a way that adapts to the memory you have.
If your machine has low memory, LayerRun should be able to stream model layers.
If your machine has more memory, LayerRun can preload more layers for better speed.
If your machine has enough memory, LayerRun can keep more of the model ready for faster inference.
This gives users control.
Instead of forcing every machine to run models in the same way, LayerRun allows the runtime strategy to change based on the available hardware.
The Problem LayerRun Solves
Local AI is growing fast.
Developers want to run models on laptops, desktops, private servers, and edge machines. They want more privacy, lower cost, and more control.
But there is a major issue.
Most large models are too heavy for normal hardware.
A small model may run easily. But bigger models can quickly become difficult because of memory limits.
The problem can be simplified like this:
Bigger model = more weights = more memory needed
Most runtimes try to load a large part of the model into memory. This improves speed, but it also creates a hard hardware requirement.
LayerRun takes a different approach.
Instead of asking only:
How can we load the full model?
LayerRun asks:
How can we run the model with the memory available?
This is the product direction of LayerRun.
It is about making model execution more flexible.
What LayerRun Does
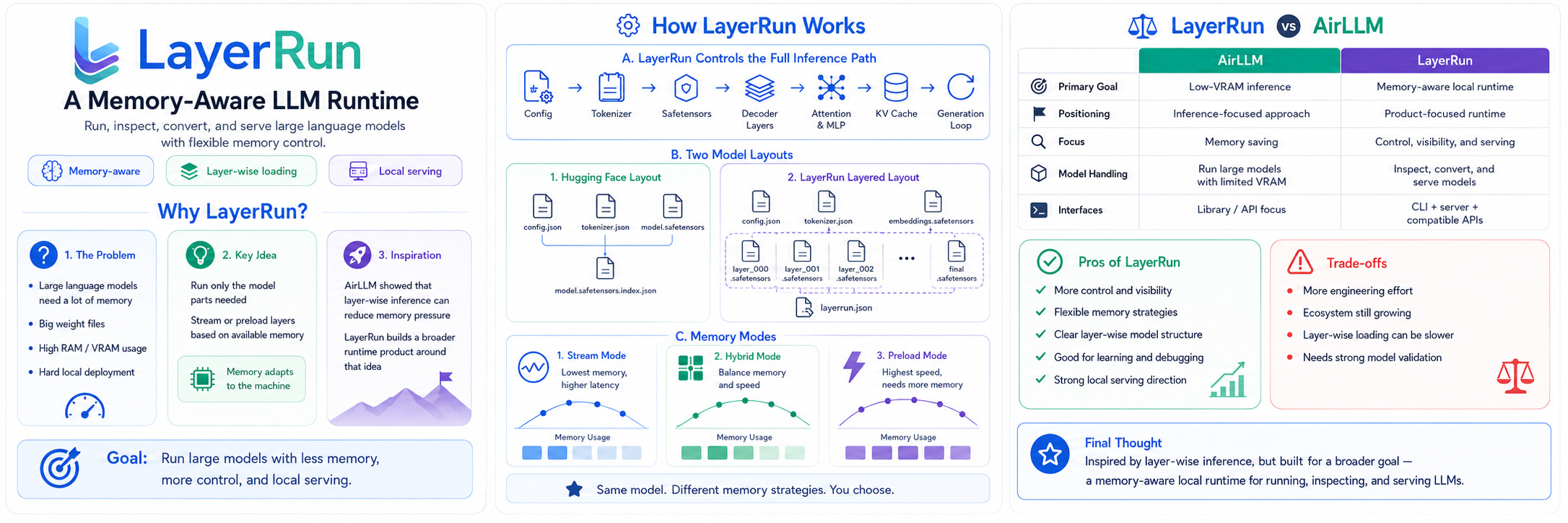
LayerRun helps convert, inspect, load, and run language models in a layer-aware way.
A normal model may come in a Hugging Face-style format like this:
config.json
tokenizer.json
model.safetensors
model.safetensors.index.jsonLayerRun can reorganize the model into a layered format:
config.json
tokenizer.json
embeddings.safetensors
layer_000.safetensors
layer_001.safetensors
layer_002.safetensors
...
final.safetensors
layerrun.jsonThis is important because transformer models already run layer by layer.
LayerRun makes the model file structure match the way the model is executed.
That means each layer can be loaded separately, inspected separately, validated separately, and managed separately.
This gives LayerRun more control over memory usage.
LayerRun as a Product
LayerRun is designed to become a practical local LLM runtime.
The product goal is not just to show that layer-wise loading is possible. The goal is to make it usable for developers.
LayerRun can grow into a tool that helps developers:
run models locally
inspect model structure
convert models into a layer-wise format
choose memory strategies
serve models through an API
debug model loading issues
understand model performance
test different backends
run models on limited hardware
This makes LayerRun useful for several types of users.
Who LayerRun Is For
1. Developers with Limited Hardware
Some developers do not have high-end GPUs.
LayerRun can help them run models with more flexible memory strategies instead of failing because the full model cannot fit into memory.
2. Local AI Builders
Many builders want to create private AI tools that run locally.
LayerRun can become a runtime layer for local AI products, desktop assistants, private chat tools, coding assistants, and offline AI systems.
3. AI Researchers and Runtime Engineers
LayerRun exposes the model execution process more clearly.
This helps people study how inference works, how memory is used, and where performance bottlenecks happen.
4. Educators and Students
LayerRun can also be used as a learning tool.
Instead of treating the model as a black box, LayerRun shows the path from model files to generated text.
This makes it useful for teaching LLM inference.
The Inspiration from AirLLM
LayerRun was inspired by one important idea from AirLLM:
A large model does not always need to be fully loaded into memory at once.
AirLLM showed that layer-wise execution can reduce memory pressure. Instead of keeping the whole model in memory, it loads the required layer, runs it, and then moves to the next layer.
In simple terms:
Load one layer
Run the layer
Move to the next layer
Continue until output is generatedThis idea is powerful because transformer models naturally work as a stack of layers.
LayerRun takes inspiration from this concept, but its product direction is different.
AirLLM mainly focuses on low-memory inference.
LayerRun focuses on building a complete runtime product around memory-aware model execution.
That means LayerRun is not only asking:
Can we run a model with less memory?
LayerRun is also asking:
Can we build a better local runtime experience for developers?
How LayerRun Is Different
LayerRun is not an AirLLM clone.
AirLLM inspired the layer-wise memory idea, but LayerRun is moving toward a broader product.
The main difference is focus.
AirLLM is mainly known for low-VRAM model running.
LayerRun is focused on:
local model execution
model conversion
layer-wise storage
memory strategy selection
runtime visibility
CLI tools
API serving
validation
future production usage
LayerRun wants to become a complete local runtime system, not only a memory-saving method.
Key Product Features
1. Layered Model Format
LayerRun can reorganize model files into separate layer files.
This makes loading more flexible and easier to control.
Instead of treating the model as one large object, LayerRun treats it as a sequence of executable parts.
2. Memory-Aware Execution
LayerRun can support multiple memory modes.
For example:
Stream mode:
Load one layer at a time
Partial preload mode:
Keep selected layers in memory
Full preload mode:
Load all layers when memory is availableThis allows LayerRun to adapt to different machines.
3. Model Inspection
LayerRun can help developers inspect model files.
This includes checking:
model configuration
tokenizer files
tensor names
tensor shapes
layer structure
missing files
unsupported layouts
This is useful when working with different open-source models.
4. CLI for Developers
LayerRun can provide a command-line interface for common model tasks.
For example:
inspect model
convert model
validate model
tokenize text
generate output
serve modelThis makes LayerRun practical for developers who want to test models quickly.
5. Local Server Direction
LayerRun can also become a local model server.
The server can expose APIs for local applications, desktop apps, backend systems, and agent frameworks.
This makes LayerRun more useful as a product because other applications can build on top of it.
6. Better Runtime Visibility
LayerRun can show what is happening during inference.
For example:
which layers are loading
how much time each step takes
where memory is used
whether layers are streamed or preloaded
how token generation behaves
This helps developers understand and debug their local AI systems.
Why LayerRun Matters
LayerRun matters because local AI needs more than just models.
It needs better runtime tools.
Today, many developers can download open-source models. But running them efficiently is still difficult.
LayerRun tries to make this easier by focusing on three things:
memory control
runtime visibility
local serving
These three ideas make LayerRun valuable as a product.
It is not only about making a model run once.
It is about giving developers a runtime they can understand, configure, and build on.
Pros of LayerRun
1. Better Memory Control
LayerRun can adjust how much of the model stays in memory.
This is useful for machines with different hardware limits.
2. More Flexible Local AI
LayerRun can help developers run AI locally instead of depending only on cloud GPUs.
This can reduce cost and improve privacy.
3. Clear Model Organization
The layered model format makes the model easier to inspect and manage.
This is useful for debugging and learning.
4. Developer-Friendly CLI
LayerRun can become a practical tool for model inspection, conversion, validation, generation, and serving.
5. Strong Product Direction
LayerRun has the potential to become more than an experiment.
It can become a local AI runtime platform for developers, researchers, and AI product builders.
Current Challenges
LayerRun is still early.
There are several important challenges to solve.
1. Speed
Layer-wise loading can reduce memory usage, but it can also slow down generation.
Reading layers from disk repeatedly is expensive.
LayerRun needs features like:
layer preloading
async prefetching
better caching
faster backends
optimized generation
quantization support
2. Model Support
Different model families have different structures.
LayerRun needs strong support for models like:
Qwen
Llama
Mistral
Gemma
other popular open models
Good model support is important for real product adoption.
3. Validation
A runtime must produce correct output.
LayerRun needs to compare its output with trusted runtimes and validate:
token IDs
logits
generated text
tokenizer behavior
layer outputs
final responses
Correctness is more important than speed in the early stage.
4. Developer Experience
For LayerRun to become a real product, it must be easy to use.
The CLI should be simple.
The error messages should be clear.
The model conversion process should be smooth.
The server should be easy to start.
A good runtime is not only technically strong. It must also feel good to use.
LayerRun’s Product Vision
LayerRun can become a memory-aware local LLM runtime.
The product vision is:
Give developers a simple way to run, inspect, convert, and serve large language models with flexible memory control.
This vision makes LayerRun different from a normal inference script.
LayerRun can become a complete runtime layer for local AI systems.
A developer should be able to use LayerRun to:
Download a model
Inspect it
Convert it
Choose a memory mode
Run generation
Serve it through an API
Monitor performance
Improve the runtime strategyThat is the real product direction.
Final Thought
LayerRun is built around a simple but important idea:
Large language models should be easier to run on the hardware people already have.
AirLLM inspired the layer-wise memory idea, showing that models do not always need to be fully loaded into memory at once.
LayerRun takes that inspiration and moves toward a broader product.
It is not only about low-memory inference.
It is about creating a local LLM runtime that gives developers control, visibility, and flexibility.
The goal is to make LayerRun a useful product for local AI builders.
A runtime that can inspect models.
A runtime that can convert models.
A runtime that can choose memory strategies.
A runtime that can serve models locally.
A runtime that helps developers understand what is happening.
LayerRun is still early, but the direction is clear.
It is not just a technical experiment.
It is a product for memory-aware local AI execution.
GtiHub Repo : https://github.com/ceylonai/layerrun